A few months ago, I wrote an article on web speech recognition using TensorflowJS. Even though it was super interesting to implement, it was cumbersome for many of you to extend. The reason was pretty simple: it required a deep learning model to be trained if you wanted to detect more words than the model I provided, which was pretty basic.
For those of you who needed a more practical approach, that article wasn’t enough. Following your requests, I’m writing today about how you can bring full speech recognition to your web applications using the Web Speech API.
But before we address the actual implementation, let’s understand some scenarios where this functionality may be helpful:
- Building an application for situations where it is not possible to use a keyboard or touch devices. For example, people working in the field of special globes make interactions with input devices hard.
- To support people with disabilities.
- Because it’s awesome!
What’s the secret to powering web apps with speech recognition?
The secret is Chrome (or Chromium) Web Speech API . This API, which works with Chromium-based browsers, is fantastic and does all the heavy work for us, leaving us to only care about building better interfaces using voice.
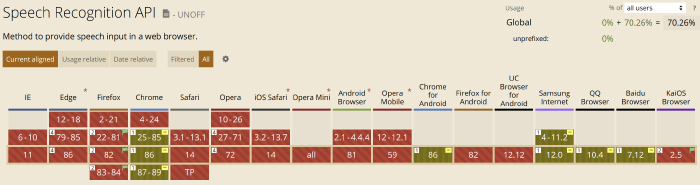
However incredible this API is, as of Nov 2020, it is not widely supported, and that can be an issue depending on your requirements. Here is the current support status. Additionally, it only works online, so you will need a different setup if you are offline.

Naturally, this API is available through JavaScript, and it is not unique or restricted to React. Nonetheless, there’s a great React library that simplifies the API even more, and it’s what we are going to use today.
Feel free to read the documentation of the Speech Recognition API on MDN Docs if you want to do your implementation on vanilla JS or any other framework.
[Read: ]
Hello world, I’m transcribing
We will start with the basics, and we will build a Hello World app that will transcribe in real-time what the user is saying. Before doing all the good stuff, we need a good working base, so let’s start setting up our project. For simplicity, we will use create-react-app to set up our project.

Next, we will work on the file App.js. CRA (create-react-app) creates a good starting point for us. Just kidding, we won’t need any of it, so start with a blank App.js file and code with me.
Before we can do anything, we need the imports:

Pretty easy, right? Let’s see in detail what we are doing, starting with the useSpeechRecognition hook.
This hook is responsible for capturing the results of the speech recognition process. It’s our gateway to producing the desire results. In its simplest form, we can extract the transcript of what the user is saying when the microphone is enabled as we do here:

Even when we activate the hook, we don’t start immediately listening; for that, we need to interact with the object SpeechRecognition that we imported at the beginning. This object exposes a series of methods that will help us control the speech recognition API, methods to start listening on the microphone, stop, change languages, etc.
Our interface simply exposes two buttons for controlling the microphone status; if you copied the provided code, your interface should look and behave like this:
Hello world!
Start listening for transcript:
If you tried the demo application, you might have noticed that you had missing words if you perhaps paused after listening. This is because the library by default sets this behavior, but you can change it by setting the parameter continuous on the startListening method, like this:

Compatibility detection
Our app is nice! But what happens if your browser is not supported? Can we have a fallback behavior for those scenarios? Yes, we can. If you need to change your app’s behavior based on whether the speech recognition API is supported or not, react-speech-recognition has a method for exactly this purpose. Here is an example:

Detecting commands
So far, we covered how to convert voice into text, but now we will take it one step further by recognizing pre-defined commands in our app. Building this functionality will make it possible for us to build apps that can fully function by voice.
If we need to build a command parser, it could be a lot of work, but thankfully, the speech recognition API already has a built-in command recognition functionality.
To respond when the user says a particular phrase, you can pass in a list of commands to the useSpeechRecognition hook. Each command is an object with the following properties:
-
command: This is a string or RegExp representing the phrase you want to listen for -
callback: The function that is executed when the command is spoken. The last argument that this function receives will always be an object containing the following properties: -
resetTranscript: A function that sets the transcript to an empty string -
matchInterim: Boolean that determines whether “interim” results should be matched against the command. This will make your component respond faster to commands, but also makes false positives more likely – i.e. the command may be detected when it is not spoken. This is false by default and should only be set for simple commands. -
isFuzzyMatch: Boolean that determines whether the comparison between speech and command is based on similarity rather than an exact match. Fuzzy matching is useful for commands that are easy to mispronounce or be misinterpreted by the Speech Recognition engine (e.g. names of places, sports teams, restaurant menu items). It is intended for commands that are string literals without special characters. If command is a string with special characters or a RegExp, it will be converted to a string without special characters when fuzzy matching. The similarity that is needed to match the command can be configured with fuzzyMatchingThreshold. isFuzzyMatch is false by default. When it is set to true, it will pass four arguments to callback:- The value of
command - The speech that matched command
- The value of
- The similarity between command and the speech
- The object mentioned in the callback description above
-
fuzzyMatchingThreshold: If the similarity of speech to command is higher than this value when isFuzzyMatch is turned on, the callback will be invoked. You should set this only if isFuzzyMatch is true. It takes values between 0 (will match anything) and 1 (needs an exact match). The default value is 0.8.
Here is an example of how to pre-define commands for your application:

Conclusion
Thanks to Chrome’s speech recognition APIs, building voice-activated apps couldn’t be easier and more fun. Hopefully, in the near future, we’ll see this API supported by more browsers and with offline capabilities. Then, it will become a very powerful API that may change the way we build the web.
This article was originally published on Live Code Stream by Juan Cruz Martinez (twitter: @bajcmartinez), founder and publisher of Live Code Stream, entrepreneur, developer, author, speaker, and doer of things.
Live Code Stream is also available as a free weekly newsletter. Sign up for updates on everything related to programming, AI, and computer science in general.