One of the key challenges that marketing teams must solve is allocating their resources in a way that minimizes “cost per acquisition” (CPA) and increases return on investment. This is possible through segmentation, the process of dividing customers into different groups based on their behavior or characteristics.
Customer segmentation can help reduce waste in marketing campaigns. If you know which customers are similar to each other, you’ll be better positioned to target your campaigns at the right people.
Customer segmentation can also help in other marketing tasks such as product recommendations, pricing, and up-selling strategies.
Customer segmentation was previously a challenging and time-consuming task, that demanded hours of manually poring over different tables and querying the data in hopes of finding ways to group customers together. But in recent years, it has become much easier thanks to machine learning, artificial intelligence algorithms that find statistical regularities in data. Machine learning models can process customer data and discover recurring patterns across various features. In many cases, machine learning algorithms can help marketing analysts find customer segments that would be very difficult to spot through intuition and manual examination of data.
Customer segmentation is a perfect example of how the combination of artificial intelligence and human intuition can create something that is greater than the sum of its parts.
The k-means clustering algorithm

Machine learning algorithms come in different flavors, each suited for specific types of tasks. Among the algorithms that are convenient for customer segmentation is k-means clustering.
K-means clustering is an unsupervised machine learning algorithm. Unsupervised algorithms don’t have a ground truth value or labeled data to assess their performance against. The idea behind k-means clustering is very simple: Arrange the data into clusters that are more similar.
[Read: ]
For instance, if your customer data includes age, income, and spending score, a well-configured k-means model can help divide your customers into groups where their attributes are closer together. In this setting, similarity between clusters is measured by calculating the difference between the age, income, and spending score of the customers.
When training a k-means model, you specify the number of clusters you want to divide your data into. The model starts with randomly placed centroids, variables that determine the center of each cluster. The model goes through the training data and assigns them to the cluster whose centroid is closer to them. Once all the training instances are classified, the parameters of the centroids are readjusted to be at the center of their clusters. The same process repeats, with the training instances being reassigned to the finetuned centroids and the centroids readjusted based on the rearrangement of the data points. At one point, the model will converge, iterating over the data will not result in training instances switching clusters and centroids changing parameters.
Determining the right number of customer segments
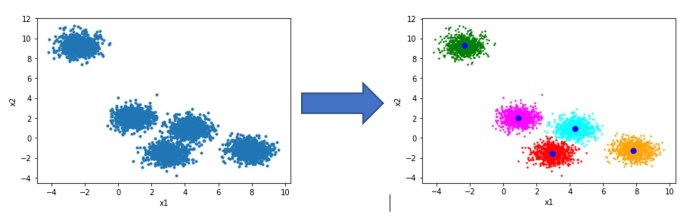
One of the keys to the successful use of the k-means machine learning algorithm is determining the number of clusters. While a model will converge on any number of clusters you provide it, not every configuration is suitable. In some cases, a quick visualization of the data can reveal the logical number of clusters the model should contain. For instance, in the following image, the training data has two features (x1 and x2), and mapping them on a scatter plot reveals five easily identifiable clusters.

When your problem has three features (e.g., x1, x2, x3), your data can be visualized in 3D space, where it’s harder to spot clusters. Beyond three features, visualizing all features in one image is impossible, and you need to use other tricks, such as using a scatterplot matrix to visualize the correlations of different pairs of features.

Another trick that can help in clustering the data is dimensionality reduction, machine learning techniques that examine the correlations in the data points and remove features that are spurious or contain less information. Dimensionality reduction can simplify your problem space and make it easier to visualize the data and spot clustering opportunities.
But in many cases, the number of clusters is not evident even with the use of the abovementioned techniques. In these cases, you’ll have to experiment with different numbers of clusters until you find one that is optimal.
But how do you find the optimal configuration? K-means models can be compared by their inertia, which is the average distance between the instances in a cluster and its centroid. In general, models with lower inertia are more coherent.
But inertia alone is not enough to evaluate the performance of your machine learning model. Increasing the number of clusters will always reduce the distance between instances and their cluster centroids. And when every single instance becomes its own cluster, the inertia will drop to zero. But you don’t want to have a machine learning model that assigns one cluster per customer.
One efficient technique to find the optimal number of clusters is the elbow method, where you gradually increase your machine learning model until you find the point where adding more clusters won’t result in a significant drop in the inertia. This is called the elbow of the machine learning model. For instance, in the following image, the elbow stands at four clusters. Adding more clusters beyond that will result in an inefficient machine learning model.

Putting k-means clustering and customer segments to use
Once trained, your machine learning model can determine the segment to which new customers belong by measuring their distance to each of the cluster centroids. There are many ways you can put this to use.
For instance, when you get a new customer, you’ll want to provide them with product recommendations. Your machine learning model will help you determine your customer’s segment and the most common products associated with that segment.
In product marketing, your clustering algorithm will help readjust your campaigns. For instance, you can start an ad campaign with a random sample of customers that belong to different segments. After running the campaign for a while, you can examine which segments are more responsive and refine your campaign to only display ads for members of those segments. Alternatively, you can run several versions of your campaign and use machine learning to segment your customers based on their responses to the different campaigns. In general, you’ll have many more tools to test and tune your ad campaigns.

K-means clustering is a fast and efficient machine learning algorithm. But it’s not a magic wand that will quickly turn your data into logical customer segments. You must first define the setting of your marketing campaigns and the kind of features that will be relevant to them. For instance, if your campaigns will be targeted at specific locales, then geographical location will not be a relevant feature, and you’re better off filtering your data for that specific region. Likewise, if you’ll be promoting a health product for men, then you should filter your customer data to only include men and avoid including gender as one of the features of your machine learning model.
And in some cases, you’ll want to include additional information, such as the products they have purchased in the past. In this case, you’ll need to create a customer-product matrix, a table that has customers as rows and the items as columns and the number of items purchased at the intersection of each customer and item. If the number of products are too many, you might consider creating an embedding, where products are represented as values in multidimensional vector space.
Overall, machine learning is a very effective tool in marketing and customer segmentation. It will probably not replace human judgment and intuition any time soon, but it can help augment human efforts to levels that were previously impossible.
This article was originally published by Mona Eslamijam on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech and what we need to look out for. You can read the original article here.
Published January 20, 2021 — 10:00 UTC